We introduce XBRL2Vec, a financial data engine designed to vectorize corporate filings into structured representations for next-generation capital allocation systems. Unlike traditional investment frameworks that rely on backward-looking price series or simplistic ratio-based metrics, XBRL2Vec extracts and embeds GAAP-tagged fundamentals, narrative disclosures, and risk language into multi-dimensional vectors. The result is a flexible, machine-readable representation of a firm’s financial and strategic position—enabling downstream AI systems to allocate capital in contextually grounded, economically meaningful ways.
1. Introduction
Financial markets are inundated with raw disclosure data—yet most algorithmic trading systems fail to incorporate it meaningfully. Traditional quantitative systems emphasize historical prices, volume, and derived indicators, leaving narrative content and detailed financial fundamentals underutilized.
XBRL2Vec addresses this gap by converting raw corporate filings (e.g., 10-K, 10-Q) into rich numerical representations. By marrying fundamental analysis with natural language processing (NLP) and representation learning, XBRL2Vec makes it possible for AI agents to reason over qualitative disclosures and quantitative performance with the same precision.
2. System Overview
2.1 Architecture
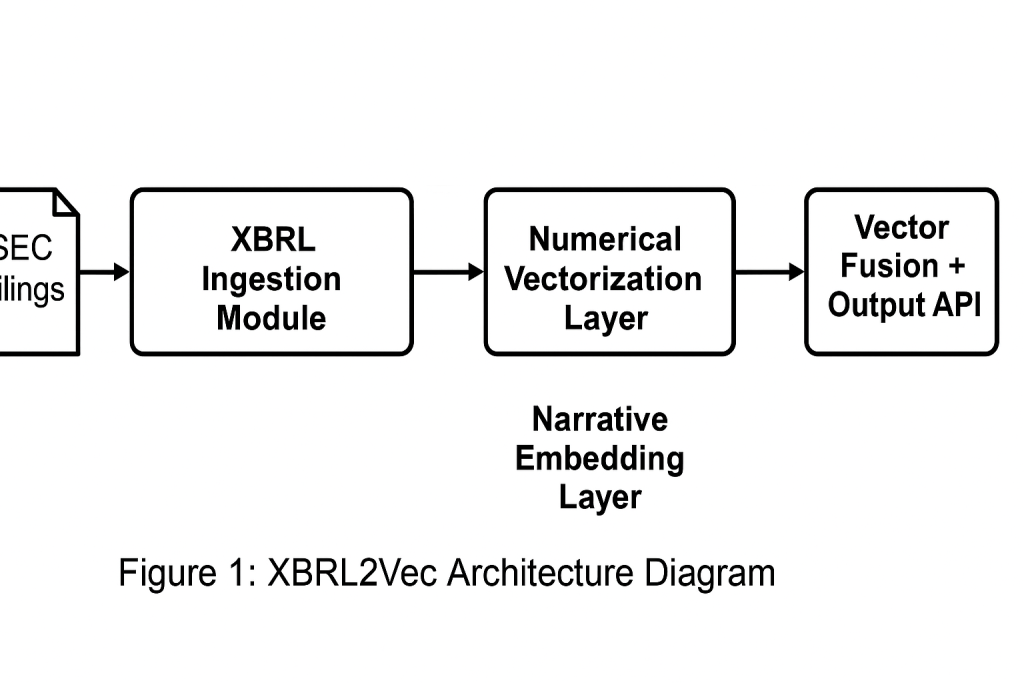
The XBRL2Vec pipeline consists of four major components:
XBRL Ingestion Module
Parses structured SEC filings using US GAAP taxonomy
Handles footnotes, tables, nested hierarchies
Numerical Vectorization Layer
Standardizes financial statement elements (revenue, margins, assets, etc.)
Extracts MD&A, risk factors, legal contingencies, etc.
Uses transformer-based models (e.g., FinBERT, LegalBERT) to generate embeddings
Vector Fusion + Output API
Combines numerical and narrative embeddings
Outputs composite firm vectors for downstream modeling
Figure 1: XBRL2Vec Architecture Diagram (Include a block diagram showing ingestion → vectorization → fusion → API output)
3. Methods
3.1 Numerical Processing
We convert GAAP-tagged elements into structured tensors by:
Mapping raw disclosures into a fixed schema
Time-normalizing (TTM, quarterly change)
Scaling (industry-relative or market percentile)
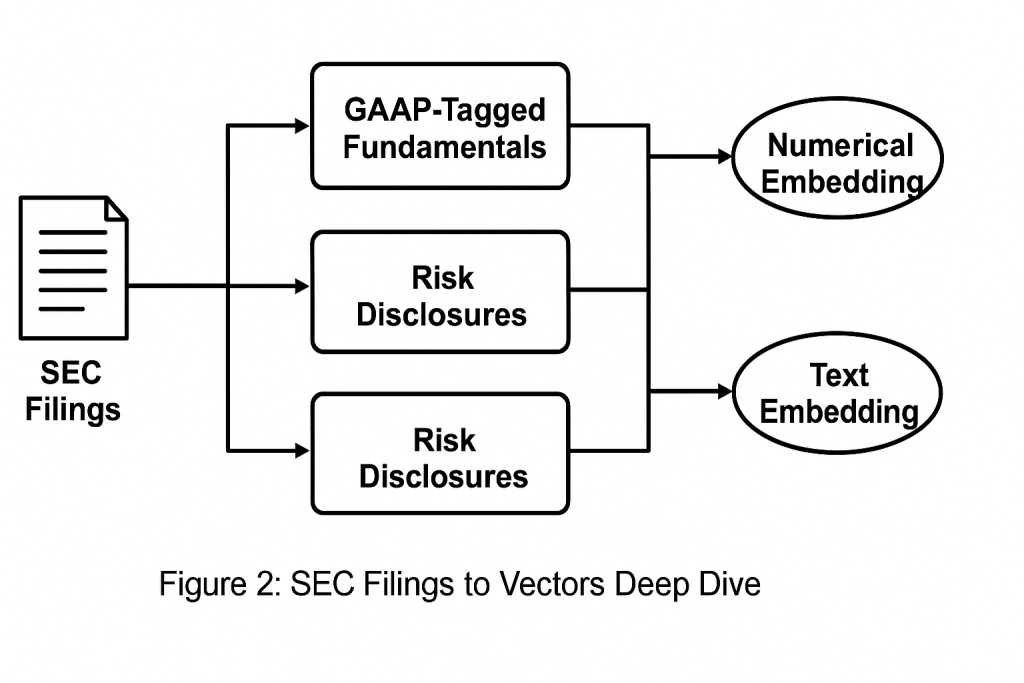
3.2 Narrative Embedding
Text sections are split and embedded using:
Pretrained financial/legal transformers
Topic modeling (optional) for dimensional reduction
Sentence-level embeddings pooled into document vectors
Figure 2: Example Embedding: Risk Disclosure → Vector Space
4. Use Cases
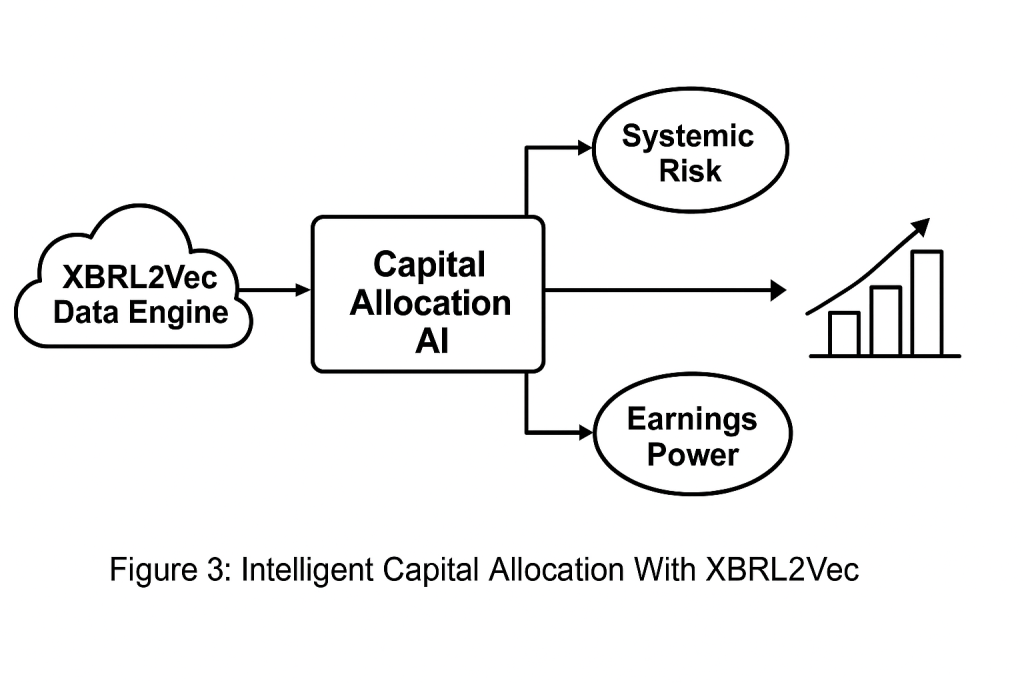
Earnings Quality Forecasting Predict misstatements, restatements, or volatility based on narrative risk language + earnings dynamics
Systemic Risk Assessment Vector clustering to detect sector-wide exposure patterns from risk factors
Capital Allocation Layer (AI-Ready) Use firm vectors as input to reinforcement learning agents or allocation optimizers
5. Results (Prototype Stage)
Preliminary tests on ~1,000 S&P 500 filings show that narrative embeddings:
Improve earnings prediction accuracy vs. numerical-only baselines
Cluster meaningfully across sectors and business models
Enable semantic comparison of companies independent of ticker/price
Figure 3: UMAP projection of firm vectors showing sectoral separation
6. Future Work
Full EDGAR stream parsing and real-time inference pipeline
Integration with TradingLogic.ai execution engine
Plug-and-play compatibility with capital allocation models (RL agents, optimization systems)
7. Conclusion
XBRL2Vec represents a foundational shift in financial modeling—from signals to structured intelligence. By embedding both the numbers and the narratives, it allows machines to operate with a richer, more human-like context—bridging the gap between data and reasoned capital allocation.